はじめに
chrome拡張機能を作ろうと思ったんだけど、手動でやるといろいろ面倒だったので、こないだリリースしたらしいフレームワーク Plasmo を使ってみた。それをまとめる。
www.plasmo.com
やってみる
もうさっそくやっちゃうよ。
Plasmoをinit
$ pnpm create plasmo
.../Library/pnpm/store/v3/tmp/dlx-88105 | +2 +
Packages are hard linked from the content-addressable store to the virtual store.
Content-addressable store is at: /Users/ayumu-1212/Library/pnpm/store/v3
Virtual store is at: ../../Library/pnpm/store/v3/tmp/dlx-88105/node_modules/.pnpm
.../Library/pnpm/store/v3/tmp/dlx-88105 | Progress: resolved 2, reused 0, downloaded 2, added 2, done
🟣 Plasmo v0.80.0
🔴 The Browser Extension Framework
🟡 Extension name: auto-diary
🟡 Extension description: An extension that automatically measures the engineer's daily progress.
🟡 Author name: ayumuabe1434@gmail.com
🔵 INFO | Creating new project with popup
🔵 INFO | Installing dependencies...
Downloading registry.npmjs.org/typescript/5.1.6: 7.15 MB/7.15 MB, done
Downloading registry.npmjs.org/@parcel/transformer-js/2.9.3: 45.7 MB/45.7 MB, done
WARN deprecated stable@0.1.8: Modern JS already guarantees Array#sort() is a stable sort, so this library is deprecated. See the compatibility table on MDN: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/sort#browser_compatibility
Downloading registry.npmjs.org/@swc/core-darwin-arm64/1.3.69: 12.8 MB/12.8 MB, done
Downloading registry.npmjs.org/@swc/core-darwin-arm64/1.3.66: 12.1 MB/12.1 MB, done
Packages: +544
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Packages are hard linked from the content-addressable store to the virtual store.
Content-addressable store is at: /Users/ayumu-1212/Library/pnpm/store/v3
Virtual store is at: node_modules/.pnpm
node_modules/.pnpm/@parcel+watcher@2.1.0/node_modules/@parcel/watcher: Running install script, done in 785ms
node_modules/.pnpm/sharp@0.32.1/node_modules/sharp: Running install script, done in 4.6s
Progress: resolved 607, reused 1, downloaded 543, added 544, done
node_modules/.pnpm/@swc+core@1.3.66/node_modules/@swc/core: Running postinstall script, done in 345ms
node_modules/.pnpm/@swc+core@1.3.69/node_modules/@swc/core: Running postinstall script, done in 816ms
node_modules/.pnpm/esbuild@0.18.13/node_modules/esbuild: Running postinstall script, done in 1s
node_modules/.pnpm/msgpackr-extract@3.0.2/node_modules/msgpackr-extract: Running install script, done in 1.2s
node_modules/.pnpm/lmdb@2.7.11/node_modules/lmdb: Running install script, done in 1s
dependencies:
+ plasmo 0.80.0
+ react 18.2.0
+ react-dom 18.2.0
devDependencies:
+ @plasmohq/prettier-plugin-sort-imports 4.0.1
+ @types/chrome 0.0.241
+ @types/node 20.4.2
+ @types/react 18.2.15
+ @types/react-dom 18.2.7
+ prettier 3.0.0
+ typescript 5.1.6
WARN Issues with peer dependencies found
.
└─┬ plasmo 0.80.0
└─┬ @plasmohq/parcel-config 0.38.4
└─┬ @parcel/config-default 2.9.3
└─┬ @parcel/optimizer-htmlnano 2.9.3
└─┬ htmlnano 2.0.4
└── ✕ unmet peer svgo@^3.0.2: found 2.8.0 in @parcel/optimizer-htmlnano
Done in 34.2s
🔵 INFO | Initializing git project...
🟢 DONE | Your extension is ready in: /Users/ayumu-1212/Documents/develop/auto-diary
To start hacking, run:
cd auto-diary
pnpm dev
Visit https://docs.plasmo.com for documentation and more examples.
おーーできた。階層構造は以下。
.
├── README.md
├── assets
│ └── icon.png
├── node_modules/
├── package.json
├── pnpm-lock.yaml
├── popup.tsx
└── tsconfig.json
buildして、公開するbuildファイルを作ってみる。
$ pnpm build
> auto-diary@0.0.1 build /Users/ayumu-1212/Documents/develop/auto-diary
> plasmo build
🟣 Plasmo v0.80.0
🔴 The Browser Extension Framework
🔵 INFO | Prepare to bundle the extension...
🔵 INFO | Loaded environment variables from: []
🟢 DONE | Finished in 849ms!
$ tree
.
├── README.md
├── assets
│ └── icon.png
├── build
│ ├── chrome-mv3-dev
│ │ ├── icon128.plasmo.c11f39af.png
│ │ ├── icon16.plasmo.9f44d99c.png
│ │ ├── icon32.plasmo.83dbbbab.png
│ │ ├── icon48.plasmo.a78c509e.png
│ │ ├── icon64.plasmo.15206795.png
│ │ ├── manifest.json
│ │ ├── plasmo-default-background.e198ef58.js
│ │ ├── popup.7d3dc21e.js
│ │ └── popup.html
│ └── chrome-mv3-prod
│ ├── icon128.plasmo.3c1ed2d2.png
│ ├── icon16.plasmo.6c567d50.png
│ ├── icon32.plasmo.76b92899.png
│ ├── icon48.plasmo.aced7582.png
│ ├── icon64.plasmo.8bb5e6e0.png
│ ├── manifest.json
│ ├── popup.100f6462.js
│ └── popup.html
├── node_modules/
├── package.json
├── pnpm-lock.yaml
├── popup.tsx
└── tsconfig.json
これでbuildができたね。公開してみよう。
いったん表示までしてみよう。ぼくはbraveを使っているのでここをブラウザで開く。
brave://extensions/
そして右上の デベロッパーモード をオンにする。
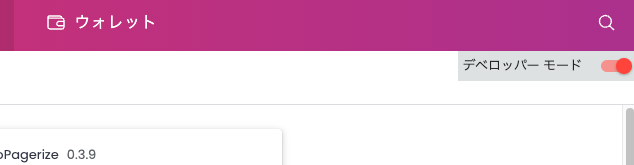
そして、[パッケージ化されていない拡張機能を読み込む] を押し、 build/chrome-mv3-dev を選択する。
すると、さっそく読み込まれて表示されている!!
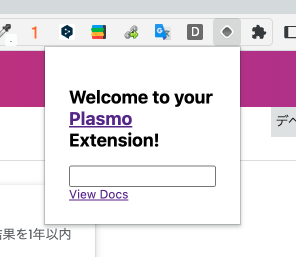
chromeの履歴を取得できるようにしてみる。
最初の立ち上げ時はコードはこのようになっている。
import { useState } from "react"
function IndexPopup() {
const [data, setData] = useState("")
return (
<div
style={{
display: "flex",
flexDirection: "column",
padding: 16
}}>
<h2>
Welcome to your
<a href="https://www.plasmo.com" target="_blank">
{" "}
Plasmo
</a>{" "}
Extension!
</h2>
<input onChange={(e) => setData(e.target.value)} value={data} />
<a href="https://docs.plasmo.com" target="_blank">
View Docs
</a>
</div>
)
}
export default IndexPopup
まずは、history パーミッションをmanifest.jsonに設定しないといけない。
直接書き込むのではなく、package.jsonに以下を追記する。
"manifest": {
"host_permissions": [
"https://*/*"
],
+ "permissions": [
+ "history"
+ ]
}
こうすることで、manifest.json に自動的に反映された。
popup.tsx を編集する。
import { useState } from "react"
function IndexPopup() {
+ const [historyItems, setHistoryItems] = useState<chrome.history.HistoryItem[]>([])
+
+ const getHistory = async() => {
+ const now = new Date()
+
+ const text = ""
+ const startTime = new Date(now.getFullYear(), now.getMonth(), now.getDate() - 1, 0, 0, 0).getTime()
+ const endTime = new Date(now.getFullYear(), now.getMonth(), now.getDate(), 0, 0, 0).getTime()
+ const maxResults = 10
+ const items = await chrome.history.search({
+ text,
+ startTime,
+ endTime,
+ maxResults,
+ })
+ setHistoryItems(items)
+ }
return (
<div
style={{
display: "flex",
flexDirection: "column",
padding: 16
}}>
<h2>
Welcome to your
<a href="https://www.plasmo.com" target="_blank">
{" "}
Plasmo
</a>{" "}
Extension!
</h2>
+ <button id="getHistory" onClick={getHistory}>getHistory</button>
+ <div>
+ <ul>
+ {historyItems.map((item) => (<li id={item.id} key={item.id}>{item.title}</li>))}
+ </ul>
+ </div>
</div>
)
}
export default IndexPopup
いいねぇ、ボタンを押したら検索履歴が表示できるようになった。
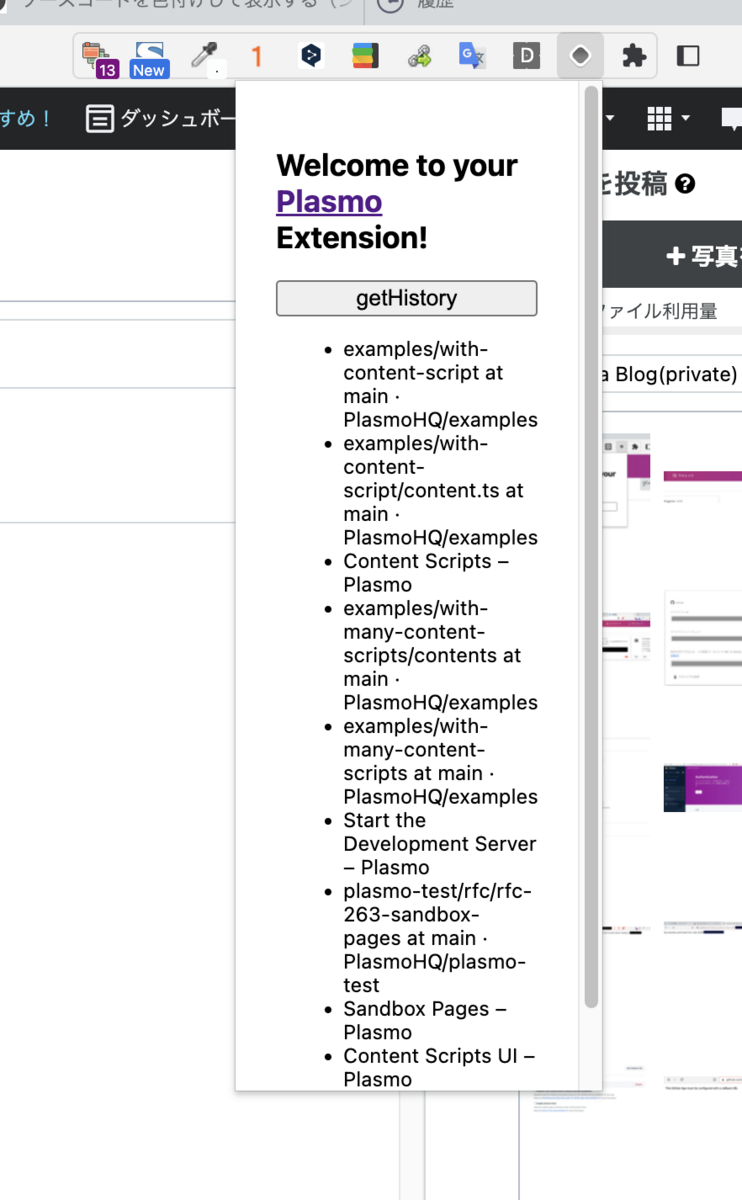
とりあえずここまで!